
A Deep Dive into Building AI Agents
Introduction
Audience
What do we mean by AI Agent?
How we build agentic systems
LLMs are probability calculators
The deterministic v. autonomous trade-off
Agent Tools
The ingredients to make an agent
Understanding Agent Capabilities
The Agent Tech Stack
Agent (Human) Interface
Agent Instructions
Agent Orchestration
Choosing The LLM
Tools
Context & Memory
RAG
Evals and Observability
Open Source Agents
Advanced Topics
Related Reading
Agents In Action
Introduction
The following is a practical deep-dive into building AI agents. Building working solutions on the emerging technical stack of LLMs and agentic architectures requires mastering a new set of components and solution layers. We hope to provide a guide through this new world and offer some recommendations for how to think about leveraging the new “AI stack” to improve your business.
We will start with a little tour of the theoretical underpinnings for AI agents, then move on to describe the technology layers needed to build a complete solution.
–Scott Persinger (scottp@supercog.ai) and Alex Osborne (alexo@supercog.ai)
Audience
This guide is intended not only for developers and solution architects, but also managers and domain experts looking to understand how this next generation of AI capabilities can improve their businesses.
What do we mean by AI Agent?
“AI systems” generally refer to any application which uses a Generative AI model (typically an LLM - a Large Language Model) as a key part of its function. Beyond this very general description, we can start to define some specific architectures for common AI systems:
- Chatbot. This application type captures the original “Chat GPT” application - an AI system which accepts natural language questions and generates a response based on the training data of a large language model.
- AI Workflow. This application employs a programmer-determined workflow of steps where some of those steps will use an LLM to generate text or accomplish another singular task.
- AI Agent. A semi-autonomous program which uses an LLM to determine the steps of execution for the program.
(see workflow vs. “agent” from Anthropic.)
We define an AI Agent as:
A software program built to accomplish tasks, where the flow of execution is controlled by an LLM, and the agent is provided a set of “tools” which it can use to affect its environment.
How we build agentic systems
While doing research with some early Large Language Models, AI researchers observed that you could ask an LLM to create a plan of action to accomplish any task. If you then assumed you had some system which could execute each action, then you could feed the observations of the results of those actions BACK to the LLM in a loop, until the LLM determined that the task was completed. This architecture was coined ReACT in an influential research paper.
To implement actions, OpenAI defined a protocol for function calling. The idea was that a user would provide a text description of a function to the LLM, and then tell the LLM that it could “call” that function by generating a well-formed block of JSON text output:
LLM system prompt:
When you receive a request, create a plan of action to accomplish the task. Each action can be either providing an answer directly, executing a function, or reporting that the task is complete.
You have a function called “get_weather”, which takes the name of a city as a parameter, and returns the weather report for that city.
Session start:
User: What is the weather in San Francisco?
(LLM inference API call…)
← response
Plan: Invoke the get_weather function for the city of San Francisco.
Action: {“function”:”get_weather”, “parameters”:{“city”:”san francisco”}}
Now, OUR application has to parse the JSON action block, then invoke the real get_weather function, and then invoke the LLM again with the full conversation plus the function response:
System: You have a function called “get_weather”, which takes the name of a city as a parameter, and returns the weather report for that city.
User: What is the weather in San Francisco?
Plan: Invoke the get_weather function for the city of San Francisco.
Action: {“function”:”get_weather”, “parameters”:{“city”:”san francisco”}}
Function response: City: San Francisco, Report: 65-75F, Sunny
(LLM inference API call…)
← response
“The weather today looks nice in San Francisco - sunny and very warm.”
This function calling protocol is at the heart of the ReAct pattern for implementing agentic AI systems. Each action that the LLM can employ to accomplish a task is expressed as a function call, and the calling application executes the functions as requested by the LLM. The function result is then returned back to the LLM so that it can observe the results and take “the next step” by requesting another action, or it can report the task as complete.
This is a basic description of a “simple AI agent”. In practice the flow and decision making of the agent can be much more complicated.
LLMs are probability calculators
How does the LLM determine which action to call to accomplish a step of its plan? The LLM uses the same probabilistic “predict the next token” approach that it uses when answering questions. The “Action” text completion is just the most likely “next word” sequence that should appear given the prompt that describes the task and the plan steps that the LLM generated.
The one twist here is that OpenAI (and other LLM makers) have trained their LLM model to restrict the possible “next word” generations to ONLY pick from one of the described functions. So, generally (!), the LLM will not try to request some action that doesn’t exist. Like if we gave this task to our agent which only has the get_weather function:
User: What is the news today from San Francisco?
Then the LLM will answer “I don’t know how to get that information.” But you could imagine that the LLM might generate this instead:
Action: {“function”:”get_news”, “parameters”:{“city”:”san francisco”}}
Because THAT is the most likely text completion given our task plan. The term of art for this is hallucination - that the LLM “imagines” a result that isn’t “true”. But the term doesn’t quite capture it, since obviously there could be a get_news function.
As we mentioned, the LLM has been trained NOT to hallucinate function calls. But guess what - they still will do so, on occasion. Sometimes your agent will try to call a function that doesn’t exist in its attempts to accomplish a task. Generally this happens in extraordinary cases or with “less instructable” LLMs like some of the open source models.
The deterministic v. autonomous trade-off
It is reasonable to ask the question: how can I create a reliable software program if the LLM’s behavior is non-deterministic? Good question! If your goal is “really reliable”, then the answer may be “it’s very, very hard”. We can create guardrails and design our agents so that they achieve “high 90s percentage” predictable behavior, but getting above 99% may be very difficult.
This means that AI agents are generally not a good solution when you need high reliability. I would not want my bank to rely on AI Agents to calculate my account balance. Joon Sung Park (the author of the seminal Generative Agents paper) suggests the terms “soft-edged problems” vs. “hard-edged problems” to describe this difference.
This is a big reason why lots of people are still building AI Workflows. In this architecture you manage the orchestration of your system via traditional deterministic code, and rely on the LLM only for more creative or error-forgiving parts of a process (like text summarization). Especially when you are building automation - getting the exact result each time may be critical.
However, it’s good to reflect on what you give up when you downgrade an Agent to a Workflow. An agent is meant to have agency - meaning that it makes decisions by itself. Rather than prescribing the plan to accomplish a task, you ask the LLM to start with the task and design the plan itself. This is both easier for you, AND means that you get a “smarter” system at the end. If your agent gets access to new functions, it can take advantage of them immediately without any new coding. If your LLM gets upgraded (smarter, faster, cheaper), which happens all the time, suddenly your agent is “smarter” without you expending any effort.
By contrast your Workflow is exactly as capable as you built it, and no more so until you spend time improving it. Our recommendations boil down to this:
- If you MUST have 100% accuracy, then build a Workflow.
- If your process can be resilient to some error rate, then an Agent will be easier to build and offer the possibility of getting better, for free, over time.
Self-correction
One thing that Agents can do quite easily, which traditional software cannot, is automatic error-correction. Suppose your weather agent gets this query:
User: What is the weather today in Hollywood California?
Action: get_weather(“hollywood, ca”)
← Error: unknown city “Hollywood”
Your Agent can easily determine that “Hollywood” is a neighborhood, not a city, and it can retry the action again:
User: What is the weather today in Hollywood California?
Action: get_weather(“hollywood, ca”)
← Error: unknown city “Hollywood”
Plan: request weather again with actual city “West Hollywood”
Action: get_weather(“west hollywood, ca”)
← The weather in West Hollywood is raining and 56 degrees today.
We have seen many, many instances where agents can solve function call and API errors that are much more complex than this scenario. In fact, we have observed more complex agents find ways to successfully accomplish tasks using a sequence of functions that we did not anticipate.
This ability to “troubleshoot” and problem solve is intrinsic in the probabilistic nature of the LLM - the fact that it can generate different “next word” completions for the same inputs. This is a deep-seated trade-off in the adoption of generative AI technology - autonomy and intelligence in exchange for predictability. So while some are throwing up their hands claiming that “nothing will really work”, the smart practitioners are figuring out where and how to apply the advantages of this new tech stack in ways that compensate for its shortcomings.
The non-deterministic nature of LLM-based systems makes them very good for “creative” use cases like getting help with writing, or generating interesting images, or even summarizing information. It makes them much less useful for tasks that require precision over a large set of data, like reconciling financial accounts. In the case of Agents, the best uses are ones where the “solution” can benefit from creative problem solving, and still be resilient to some variations in behavior.
Agent Tools
“Tools” are the term of art for functions that you have exposed to your agent that give it the capacity to interact with the world around it. The function calling protocol defined first by OpenAI has now been adopted by most of the major LLM vendors. This means that tools can generally (* - another asterisk!) be re-used by agents powered by any frontier LLM.
Note: Generally when we talk about a “Tool” we are talking about a set of related functions that implement some specific capabilities. Some simple tools offer a single function, but more complex tools might include 10 or more functions.
(The LangChain project refers to single functions as “tools” and the collection as a “toolkit”. We don’t find those terms friendly in practice - it’s easier to talk about the “Salesforce tool” or the “Image Recognition Tool” than to refer to everything as “toolkits”.)
The tools available to your agent are the gateway to every capability and action that your agent can take. Tools can represent almost any capability, and extend the abilities of your agent in almost any direction. Some of the common categories of tools include:
- Knowledge retrieval from unstructured or structured sources
- Database access, typically relying on the LLMs ability to write complex SQL queries
- Image generation and recognition (OCR)
- File and document manipulation
- Calling APIs to read or write data from other systems
- Audio (text to speech, speech to text) and video processing
Agent Tools is a large topic. Later we will delve into the design of tools and how to effectively integrate them with your agent.
The ingredients to make an agent
In our view, the “essential ingredients” to make an AI agent include:
- The LLM which acts as the “brain” of your agent
- The English language system prompt which governs your agent’s behavior
- The tools which are enabled for use by the agent
- An API or user interface for executing the agent
These are just the basics, and production systems may include significant other components:
- Short term and long term agent memory
- Retrieval Augmented Generation (RAG) backend system for indexing and retrieval
- Observability for costs and errors
- Evals system for improvement and testing
- Online learning and feedback systems
Understanding Agent Capabilities
Now that we have covered the core components of an AI agent, let’s briefly what these agents “can do”:
We can start with the core capabilities that agents inherit from their Large Language Model:
- Read and write, and speak and understand, natural language. In fact LLMs can translate easily between languages.
- Analyze images, extracting text and information.
- Generate images.
- Recall facts and information from their vast training data sets. LLMs are “knowledge experts” in almost every discipline and domain.
Beyond these “built-in” capabilities are the abilities that emerge for agentic design:
- The ability to plan (decompose a task into a sequence of steps)
- The ability to reason, by evaluating a set of input conditions against a goal condition, and “working backwards” to determining likely paths to the goal
- The ability to reflect (self-evaluate their performance on a task)
- The ability to “learn” simply by adding knowledge to their context
- The ability to “take action” via their tools
The true “magic” of AI agents is when these capabilities are combined:
- Vast domain-specific knowledge
- Specific knowledge learned “on the job”
- Ability to plan, reason, and take action
- Ability to reflect and learn, and thus to self-improve
LLM-based agents are a brand new technology, still in its infancy. But the extrapolation of the possibilities created by combining these capabilities is what has everyone so excited.
The Agent Tech Stack
Now that we’ve covered the essential basics of our agent, let’s take a high level view at our agent architecture:
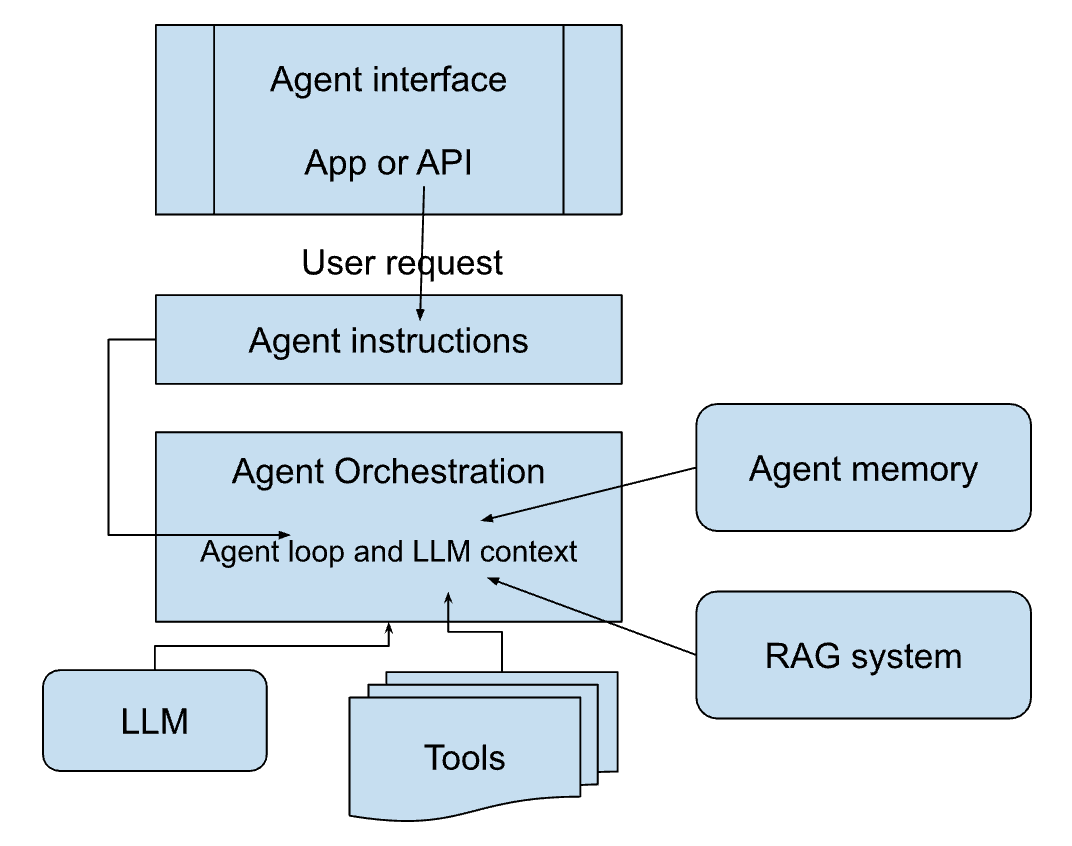
At present the “agent tech stack” market maps to this architecture as follows:

This is in no way an exhaustive map, and there are many, many competing options in every category. But we’ve attempted to capture some of the de-facto leaders and currently popular options. A good thing to remember is that Google, Microsoft and Amazon all offer some framework or service that fits into each of these boxes. But you will have to do your due diligence to find out if any of those services are actually working for folks in production.
Buy vs. Build
Before we delve more into the technical pieces of the agent architecture, we want to take some time to discuss all the options you should consider before you start building your own AI agents from scratch.
Building a single agent - v1! - dedicated to solving a single task within your company, is not necessarily a huge undertaking. With the OpenAI API, some LangChain sample code, a few open source packages, and a FastAPI interface, you can build a basic agent in a couple weeks and get to the “proof of concept” stage. This isn’t a bad approach to learn about the technology and what you can do with it.
However, getting past proof-of-concept v1 into a real production solution can be a long and expensive road. You should think critically about de-risking your agent solution (“How can I prove this agent can solve task X effectively?”) and the fastest and cheapest way to do that. Using an off the shelf product or platform can be a very cost effective way to determine the viability of your agent without you having to build every piece from scratch.
And in our experience, a lot of the risk of “can this agent solve this problem” will relate to which foundation model you are using, how clean is the data available to your agent, and how effectively do your tools enable key capabilities for the agent. Spending time creating your agent platform may not be the best investment, at least until you understand what is technically possible.
So here are some questions to consider before building from scratch:
- Is there an off the shelf product built to solve the problem I am trying to solve?
- Can I use a pre-built platform to test and iterate my solution quickly?
- Before I adopt a complex framework, can I build something simpler on a well tested API like those from OpenAI or Anthropic?
- What data will my agent need to operate effectively? Can I demonstrate an agent which uses a hand-collected sample of that data to accomplish a few instances of my task?
With those questions out of the way, let's dive into each of our pieces or agent architecture. Along the way we will share our direct learnings in each area. We will work front-to-back, starting with “agent interface” and working backwards into the implementation.
Agent (Human) Interface
Your agent needs to expose some interface to be usable - either by people or via API call from some other system.
The simplest interface is a basic API. Developers can use FastAPI or another technology to quickly expose their agent via a programmatic interface.
If you want actual people to interact with your agent, then you need a real user interface. Custom web interfaces or native mobile app interfaces are fairly complex to build. OpenAI provides a Typescript library to interact with their various APIs. Streamlit and Gradio are popular choices for building “quick and dirty” chatbot interfaces.
Vercel recently launched their AI SDK which looks to provide a set of useful building blocks for composing a web interface to your agent. We haven’t tried it yet, but it looks very promising.
Slack is becoming a popular application for hosting AI agents since it already builds on a “chat” interface natively. In fact the company recently added a dedicated “AI app” user interface to make it easy to embed conversational agents into Slack.
The newest frontier for agent interfaces is voice mode - interacting with your agent via voice command. OpenAI has a leading offering with their Realtime API which offers low-latency voice modality. These features are coming very soon to a customer support AI agent near you, but this adoption is likely just the start.
Agent Instructions
Virtually any AI agent will have some prompt that helps define the overall goal of the agent to the LLM. We refer to these as the agent instructions to disambiguate from the user prompt which is the specific request sent to your agent when it runs.
Depending on the task, your instructions could be very simple, or quite complex. When designing a generalized agent that can accomplish many simpler tasks, we often will use a similarly general prompt.
For complex tasks it can work well to express your instructions as a sequence of steps. Here are the instructions for a Meeting Prep agent which helps you research someone before meeting with them:
When the user supplies an email address plus some other identifying information, follow these instructions carefully:
1. Perform extensive web research about the company the person works for and about the person themselves
2. Confirm that the research appears to match the identity of your original input.
3. Prepare a detailed "meeting prep" report based on the information you gather.
4. Save the report as a PDF
Notice that usually you don’t need to reference the specific tools or functions that the agent should use, because you want your agent to figure these out itself. However if the agent behavior isn’t predictable enough you can always specify exactly which tools it should use at each step.
Here are some tips for writing effective agent instructions:
- Start with a simple description of your goal and see how effectively the agent can plan and execute against that goal. It can also be very effective to include an example of the response you want to get back. The more general are your instructions, the more resilient and self-directed will be the agent that results.
- Break down your instructions into separate steps when you have a strong idea of what those steps should be and you always want the agent to follow them.
- As much as possible, write your instructions as a logical, simple progression of steps. Try not to have instructions which force your agent to “jump around” in its plan.
- Try not to refer to tools by name to preserve the ability of the agent to use different tools or solve problems in different ways. But if behavior is unpredictable then you can specify tools or functions to be more prescriptive.
- If your agent is getting confused or failing its task, try breaking the task into smaller pieces and build separate agents for each piece.
- Use plain and clear language, and try to be very explicit about what you want. Usually incorrect behavior from the agent can be fixed via good “prompt engineering”, which really means just writing clearly.
- Note that the LLMs are much better with positive logic than negative logic: “Please DO X” rather than “Please DO NOT do Y”. If you need to add guards or prohibitions, it is good practice to state those as “Ground rule” items at the start of your instructions, and then express all the positive instructions in sequence. Mixing some negative condition, like “Step 3: Do this thing, but NOT in this way” doesn’t work as well.
“Agent Instructions” vs. “User Instructions”
We use the terminology of “agent instructions” as the base instructions given to your agent by the agent designer. When the agent runs, if it needs to operate on additional input, then we call these “User instructions” or “User prompts”.
Sometimes it can get confusing as to what should be in the agent instructions vs. the user prompt, because your agent can operate at many different levels of abstraction. In fact you could give your agent this single agent instruction:
Please do whatever you are asked to do.
And then anything more specific you could provide “at runtime” in the user instruction: “Please use the get_weather function and tell me the weather in San Francisco”.
Generally this is confusing, and we recommend that people write fairly prescriptive instructions to the agent to perform a single task. If you need additional tasks then you can create separate agents. However, once you have good experience building simpler agents, you may want to experiment with agents that handle multiple tasks and with more autonomy. We will talk more about this in the future work section below.
Agent Orchestration
At the center of your agent implementation is the agent orchestration. This is the software which “executes” your agent. The orchestration engine brings all the pieces together to make your agent actually run. It takes the agent instructions, defines the tools the agent can use, and takes any user instructions, and combines these pieces into a “prompt” which is fed into the LLM. The LLM plans the actions to accomplish the requested task, and it starts to issue “Action” statements which the agent core then executes, feeding the tool results back into the LLM context.
The orchestration implements the “agent loop” where it maintains the current LLM context, adding new inputs and tool results into that context, and repeatedly sending that context to the LLM for “completion” to describe the next action for the agent to take.
Here are some of the popular “agent frameworks” which people are using as their Agent Orchestration layers:
OpenAI/Anthropic API - Before adopting an open source framework, consider whether you can build directly on top of an API from Open AI or Anthropic. These APIs are well supported, and OpenAI even offers its Assistants API which is purpose built for agents. These can be easier to get started with than trying to use a more complex framework. The downside is that adopting one of these APIs likely means that your agent cannot be “retro-fitted” to use an LLM from another vendor without a lot of work.
LangChain - This is the leading agent framework, and the one we have the most experience with. The biggest knock on LangChain is that it can be quite complex and hard to get started with. LangChain has a basic “agent core” implementation from its original library, but recently they introduced LangGraph as a more expressive way to build more complex agents. One of the big advantages with LangChain is that it provides common abstractions over most of the leading LLMs, which means that you can run your agent via different LLMs without changing any code.
This happens via “adapter libraries” which LangChain builds and supports for each LLM.
LlamaIndex - This LangChain competitor framework is most well known for its RAG backend infrastructure. It includes lots of connectors and parsers for ingesting knowledge from many different systems into a RAG knowledge index. LlamaIndex added agent support in 2024.
Autogen - this is an agent framework from Microsoft. It has a lot of good research behind it.
Crew AI - This is considered the leading “team of agents” framework. Crew builds on the idea of breaking your primary goal down into separate smaller tasks and then defining an “agent” for each task, and then having those agents cooperate to achieve the final result.
Letta - This framework, originally known as MemGPT, looks to add a powerful system for memory into your agent. Letta is newer than most of these other frameworks, but recently debuted a GUI-based “agent studio” to make it easier to program new agents.
A few things to consider in your framework:
- What is tool support like? Does it come with a library of tools which you can use “out of the box” with your agent? How hard is it to build new tools?
- How can you observe the actions that your agent is taking? How do you debug it?
- How can you test your agent, and re-test it for proper behavior over time?
A quick word about latency
One of the things you will likely encounter as you build and experiment with agents, is that LLM thinking is slow. A single API call to OpenAI or Anthropic to run a “turn” of your agent can take multiple seconds, or even tens of seconds. This is glacier slow in the world of modern software.
This is so slow that one of the keys to modern web computing - the idea of a “synchronous call” - does not really work with agents. You generally do NOT want to hold an HTTP request open for many seconds. So it’s important to architect your agent core to be event driven. Running your agent should look like:
Send User input to agent →
← HTTP request completed
..start waiting for results…
(agent event received) Update interface
(agent event received) Update interface
..
(agent done)
So when designing your agent system, design to receive events asynchronously from your agent, and to detect from a “state” field in those events when your agent is “done” executing its task. How you receive asynchronous events is up to you - some popular options include using an event broker like Redis, a websocket connection, or Server-side Events protocol.
Choosing The LLM
Which LLM you use as the “brain” of your agent will have a large impact on how (well) your agent operates. There are many LLMs now which are trained on a large corpus of data and have lots of inherent “knowledge”. But to effectively execute the activities of an agent: planning, tool calling, and error correction, the LLM needs to be fine-tuned to be instructable. “Instruction following” is the term of art from LLM makers for LLMs that have been fine tuned to execute the agent plan-act-observe pattern effectively.
OpenAI is the traditional leader in this space, with GPT4 being the first LLM which could reliably power a complex agent. Since that time Anthropic has caught up to GPT4 with its Claude Sonnet model, and in some tasks Claude is now better than GPT4.
Evaluating the LLM requires considering all of these factors:
- “Intelligence” - how smart is the model at following instructions and using tools effectively
- Cost - how much do input and output tokens cost
- Speed - what is the latency for the model to generate completions. We also include a notion of “availability” in this factor since LLM API rate limits can be a significant factor with some models.
- “Openness” - a general term for how much you are in control of the model itself. Can you read its code? Can you run the model yourself so that you don’t have to share your data with anyone else?
At the moment of writing, many of these factors are in tension. We don’t yet have the open, cheap, fast, very smart model that everyone could use to power their agents. However, the development trendlines unsurprisingly point to ever smarter, cheaper, faster models, and more open availability.
Here is our “scoring” table for the current generation of frontier models, for use in AI agents, roughly ranked in our “recommended” priority order:

Note that OpenAI’s smartest models (o1 and o3) do not yet support function calling and so they can’t be used yet to power agents.
A word about gpt-4o-mini
OpenAI released their gpt-4o-mini model in the middle of 2024. It didn’t get a lot of fanfare because it was billed as just a “streamlined” version of GPT-4o. The real headline for that model was that the token cost to use the model was 30X cheaper than GPT-4o. When you are using the LLM “in a loop” to power an AI agent, this cost savings is huge. It can mean the difference between an agent that runs for “pennies” and one that runs for “dollars”!
The other thing that OpenAI did with 4o-mini is that they fine-tuned the model to be very terse. This means that when you ask the LLM to “predict the next token” it tends to return a much smaller number of tokens than 4o or Claude Sonnet. In many “AI agent” use cases this is very much what you want - you want your model to be very good at using tools, but not necessarily be super verbose about it.
The other reason this is critical is, again, cost. Remember that in the agent loop, almost every output token generated by the LLM will get fed back into the LLM as an input token in the next turn. The longer your agent runs, the longer your LLM context becomes as “history” accumulates, and the more cost you incur. (In fact, the LLM costs when running agents are completely dominated by input token costs, not output tokens.) So using a terse model is inherently cheaper than using a verbose model.
Since the introduction of gpt-4o-mini, we have adopted it as our default LLM for most agents. Sometimes we have to “upgrade” to GPT-4o or Claude in order to get the greater intelligence of those models, but only after we try Mini first.
The other LLM vendors certainly took note of 4o-mini, and now there are flavors of the Anthropic and Google models which come in “cheap, very instructable” versions for use in agents.
As you can see, the closed source models are still the clear leaders for building agents. Using an open source LLM sounds great except when your agent simply doesn’t work because it’s not smart enough to do effective planning or use tools. The Llama model from Meta is currently the only open source model that we have found usable in practice for general AI agents.
(Since this original doc, DeepSeek already took the AI world by storm with their very intelligence, open source LLM. It looks very promising, but we are still evaluating its ability to execute agentic workflows.)
Specialty Models
The discussion above focused on LLMs to power “generalized agents”. That is, agents that can take a natural language description plus a set of tools, and accomplish a variety of tasks using those pieces in a semi-autonomous way.
If you are focused on a single, specialized task, then you may be able to use a smaller or more purpose-built model to run your agent. One of our recommendations is to follow a “path to specialization”:
- Define your task
- Use a general purpose agent powered by a frontier model to attempt to accomplish the task
- Now iterate your agent instructions to be more specific and granular
- Test each instruction, in isolation, with an agent using a cheaper/smaller model
- Arrive at a prescriptive agent which operates effectively using a simpler model
The base case for this approach is building your agent using GPT-4o or Claude Sonnet, and then refining the agent so that it eventually runs with a cheaper model like GPT-4o-mini (priced at 30X less than GPT4o). But this approach can also work for OSS models like Lllama.
“Model Routing”
As you can see from this discussion, there are many trade-offs that go into choosing the LLM for your agent. And given those trade-offs, using different models for different agent use-cases is highly desirable.
If you want to run an AI agent for basic automation, something that might run every day or multiple times per day, you probably want a cheap model to use like 4o-mini. On the other hand, some agent use cases like performing web research, or generating meeting summaries, can benefit from the greater expressiveness of a model like Claude.
All of this points to the importance of being able to leverage multiple LLMs. It is the biggest argument against those who recommend “just use the OpenAI API” as a simpler way to build your agent. The complexity of adopting a framework which offers multiple “model routing” is real, but well worth the trade-off in our experience.
Tools
We introduced Agent Tools earlier - the functions you attach to your agent to allow it to take action. The idea of tools is straightforward, but the reality is a lot more complicated. In theory tools are “just functions” that your agent can call, just like any software program would call a function, like:
def read_file(self, file_name: str) -> str:
"""Returns the contents of the given file."""
return open(file_name).read()
In practice there are lots of considerations needed for building good tools.
Crafting good tool function names
The name of your function is the primary way that the LLM determines that it should call it. Yes the LLM will look at the parameters and the description string, but the name is paramount. Especially when you start attaching multiple tools to your agent, you can pretty easily get 20 or 30 functions described to the LLM, so picking good names is critical.
Remember that at present, ALL function names share the same namespace, so every tool function you give your agent sits alongside every other function for consideration by the agent.
Here are some naming guidelines:
- Make your name as logical as possible, using standard naming terms. Remember that the foundation models have been trained on TONS of open source code, so they are expecting function names like they’ve seen in that code. “Read_file”, “open_file”, “download_url”, etc… If your Agent isn’t calling your function reliably, consider whether you named it in a way that might be surprising to the LLM.
- Along with logical names, you always want to make your names very specific. The reason is because of the flat namespace. Don’t use only generic terms like “search”, “read”, or even basic “read_file”. If your tool has a particular purpose, like reading files from Google Drive, it’s better to prefix your functions:
gdrive_read_file
gdrive_search
If you name your function “read_file” then your Agent can’t use any other tool that might also use that name. - Write a good function description.
- Just as with function names, try to use logical and obvious parameter names. Things like “url”, “file_name”, “query_string”. Don’t get creative and don’t use short parameters like “x”.
- In many cases a good parameter name is enough. But you can also describe the use and potential values of your parameter in the function description for “non obvious” parameters.
Returning data other than text
LLMs have been trained on lots of plain text, and OpenAI and Anthropic have fine-tuned their models to generate and read Markdown format as well. So those are good candidates for function inputs and outputs.
If you want to return structured data, you have a few options. Remember that ultimately anything you do return will get rendered as text (or image data if you are using a vision-enabled LLM).
JSON - the LLMs understand JSON format very well, knowing both how to read and write it. This means it is reasonable to return, say, an API call result as the serialized JSON you got back from the API. JSON works well for tabular data and for hierarchical data.
CSV - Although you can return tabular data as JSON, CSV is also a decent format and takes less space than the equivalent JSON. All you do is render the header row, then the data rows using commas as separators.
HTML - the LLM can “parse” HTML effectively, but we recommend converting HTML into Markdown before returning it.
PDFs, Images, Docs files - For all of these you probably want to convert the item to text and return that to the LLM. It’s usually a good idea to also return a URL that references the original doc.
Large data and the LLM context
Remember that your agent’s context size is limited. In our experience running agents, the overall context size is dominated by the size of data returned from tools. This makes sense since user input (people typing) and LLM generated tokens are generally gonna be pretty small (hundreds or small thousands of tokens), whereas a tool can return a huge doc, or the result of a database query, and suddenly you can start getting tens of thousands of tokens into context.
We have found a few good techniques for managing large tool results:
- Return a URL referencing the “full result” which the end user can access, but don’t return the contents themselves to the agent
- Return a “preview” of the tool result, just a snippet so the LLM can understand the nature of the result (example: is it real data or just an error message).
- Return results in pages, and define tool functions for retrieving the “next page” of results.
Generally you DO NOT want to blow up the agent context with a single tool call, but you do want the LLM or the user to be able to retrieve all the results if they wish.
Context & Memory
Most LLM APIs from OpenAI and others are stateless. This means that each call to request an LLM text completion is independent of every other call. The implication of this is that if you want your agent to have a “conversation” with you, then it needs to remember the details of the conversation and provide that “chat history” every time you call the LLM for the next completion.
Agent frameworks will typically offer some built-in mechanism for maintaining the chat history for your agent. By default that history is kept in memory. Some frameworks have support for saving the history to durable storage, and other frameworks leave that to your application.
The key thing to remember is that chat history = LLM context. For your agent to “remember” something is for that thing to be included in the input context the next time that you ask for an LLM completion (the next “agent step”).
LLM context windows are finite. Originally they were like 4k or 16k, growing to 128k. More recently Google Gemini offers a 1m context window. The bigger the context, the more knowledge and memory your agent can have in order to accomplish the next task.
Although a 1m token context is awesome, with present technology the more data information is in the context, the less accurate your LLM may be. If I ask the LLM to pick a name out of a list of 10 candidates it is likely to do this correctly very often. But if I ask it to pick from a list of 10,000 names, then the odds go way down that it does this correctly every time. So for the time being, we have to consider context size as a constraint when we build and operate our agents.
Managing “short-term” memory
We refer to the information in the active LLM context as the “short term” memory of our agent. The naive implementation of an agent is that it keeps the entire history of each “chat” session in short term memory. This works fairly well with the leading LLMs, but not perfectly:
- Keeping everything in memory can be expensive, since each “next turn” of the agent will resubmit the entire memory as input context to your LLM call.
- Eventually you will exhaust the context size and get an API error from the LLM.
The simplest solution to this problem is to limit your “memory” size by discarding the oldest data in memory once the limit is exceeded. The result is that your agent “forgets” the oldest information but remembers things that happened more recently.
People have experimented with more sophisticated approaches. One simple enhancement that we have found good luck with is to truncate older, large tool results. As we discussed, large tool results (loading docs or query results into memory) are the largest consumers of memory space. So we like to leave all user prompts, tool invocations, and LLM generations in memory, but to truncate large tool results as they get older. This means if you asked your agent to “read this large PDF doc”, then you can ask questions about that doc for a number of turns. But if you now switch to a different topic with the agent, it can start forgetting that large doc.
Another approach that we really like is the idea of “progressive summarization”. Basically after each turn of your agent, you summarize older memories using a “side band” LLM call. The summarization prompt you use can get increasingly aggressive so that the older memories become “highly compressed” while mid-term memories are only moderately compressed.
RAG
Very early folks realized that giving your LLM “new knowledge” was constrained by either the costs of re-training the underlying model, or the limitations of putting information into the LLM context. Thus the idea of Retrieval Augmented Generation was conceived, which basically says “Let’s try to add appropriate content, on demand, to the LLM context before it answers a question”. If we can be smart about retrieving a subset of relevant information from a large corpus of info, then we can “extend” the knowledge of our LLM without re-training and while still respecting the limits of active short-term memory.
The classic RAG architecture used a “retrieval” step inserted in between receiving the user question and the LLM generating its response:
User question →
RAG lookup: retrieve relevant info from database →
Insert info and question into LLM context →
LLM generates the answer
The “retrieve” step basically tries to find “relevant information” that might be helpful to answering the user’s question. But how do we determine what is “relevant”? The retrieval step generally does some search into a datastore of knowledge and retrieves “chunks” that seem likely to be relevant. In most systems this happens with a combination of “keyword relevance” and “semantic relevance”. So if my question is “Who founded OpenAI?”, then first we can consider any records in our database containing those keywords (at least the non-generic ones like “OpenAI” and “founded”). Then we also search for “semantically related” info, by using “embedding vectors” and determining vector similarity. (LangChain has a good tutorial that explains all the key features of implementing RAG.)
Agentic RAG
In pre-agent RAG systems, the retrieval step was programmed by hand into the system flow. More recently, people have been moving to “agentic RAG” where instead of handling retrieval implicitly, we let the agent LLM decide to call a retrieval function that is attached as an agent tool. This approach is more flexible as the LLM can decide if “knowledge retrieval” is an appropriate action given the user query. Also this retrieval function can offer parameters like filters or term boosting that the LLM can decide to use to try to improve results.
Finally, because our agent runs in a loop, the LLM can execute multiple retrieval calls in order to try to find the best info. As a simple example the agent could retrieve by lexicographic similarity first, and THEN retrieve by semantic similarity, rather than having to rely on the implicit retrieval function to determine this mix.
How to implement RAG for your agent
Most popular agent frameworks like LangChain and LLamaIndex have good support for RAG including supporting lots of different vector databases for storage. We have seen good results using Postgres and PGVector, as well as classic libraries like Chroma and FAAIS. One consideration is whether you need multi-tenancy for your document storage or not.
Document Pipeline
You will need a system for indexing documents, converting them to text, chunking and summarizing, and storing these in your index (and updating them later). This document pipeline system (the “RAG backend”) is a whole potentially large system unto itself. Fortunately there are both open source projects, like LLamaIndex, and a burgeoning set of “RAG as service” vendors you can choose from. FWIW, we have not had good experience with the “RAG services” offered by the big cloud vendors (Google, Amazon) as they seem to have rushed them to market very quickly (Google even offers “hosted LlamaIndex”). Our recommendation is to consider “leading startups” in the space like LlamaIndex or Ragie.ai.
We prefer the “agentic RAG” architecture where the Retrieval step is defined as one or more tool functions exposed to the agent. This makes the RAG setup much more composable, and lets us tune the retrieval strategy for different agents by simply editing the agent prompt.
Storing vectors
The key part of the RAG backend is the vector database. Rather than storing documents as text, we instead chop up a document into “chunks”, calculate the embedding vector for each chunk, then store these vectors in a special database. That database allows us to search by vector similarity for related content. Popular vector databases include PGVector, based on Postgres, Weaviate, Chroma, and many many others. We generally suggest starting with open source PGVector unless you have a strong reason to prefer another database.
Getting good results
Getting good answers to lots of varied types of questions is the hard work of implementing RAG in your agent. Many RAG systems are still quite primitive, and work best for a constrained use like “give me an answer taken from this collection of help documents”, which is the classic “Knowledge Base Support Chatbot” case.
Here are some questions to consider as you plan or evaluate your RAG implementation:
- How do we handle “non-document shaped” information? Slack messages, Salesforce records, Email messages, … These things aren’t really “documents” so how you chunk and summarize and search for them probably requires a different approach than the naive one suggested for “documents”.
- How do we handle conflicting or changing information? Records typically get updated in place, but documents often generate new and potentially conflicting versions. Slack messages probably have a ton of useful info, but how much of it is correct?!
- How do we process more abstract questions like “show me a list of our customers?”. This is the kind of question that classic RAG really struggles with, but which an Agent can potentially handle much more effectively, likely by giving it some structured data input that contains the “list of customers”.
Evals and Observability
As you are building your AI agent, you will be able to observe its highest level behavior fairly easily. But sometimes you need to debug your agent and understand exactly what is happening under the covers.
Most agent APIs and frameworks offer pretty good options for manual debugging - mostly by showing traces that detail the LLM context and tool calls and results at each step of the agent loop. We have had good results using a CallbackHandler in LangChain to get debugging output from each step, which we save to a log file:

We also like LangSmith (used with LangChain) as it gives you a nice UI for examining the execution of your agent. Other frameworks offer similar tools.
It’s fine to do human testing with your agents, and depending on your use case this may be sufficient. But at some point you want to be able to prove that your agent works properly under various circumstances, and be able to re-prove those assertions later after you make changes to your system.
LLM Evals
One approach common for LLM programming is “LLM Evals”. The basic idea of “Evals” is fairly simple: we construct a set of test cases with LLM inputs matched to “expected outputs”. Then we run our system with those inputs, and compare the actual result to our expected outputs.
The “eval” part comes in the last step - comparing the actual output to the expected output. As we recall, LLMs operate probabilistically, which means that they will produce varying results from the same inputs. So generally we can’t expect that the output from our agent will “string match” exactly to our expected output. Instead we just need the output to “mostly, semantically match” our expected output. So to do this, we use the LLM again to compare the actual output with the expected output, and we ask “how similar are these outputs”. This gives us a score that reasonably indicates if the agent “matched” our expected output or not.
Classic LLM evals operate at the level of the “LLM completion”. We are comparing singular text outputs to expected outputs. But once you get into the realm of Agents, this primitive eval isn’t so useful since what you really want to know is whether the agent accomplished its task or not.
Agent Tests
Instead of thinking in terms of “evals”, we have mostly adopted a more traditional software testing approach, but applied it to agents. We write tests as prompts to give to the agent that are constructed to generate an easily testable string in their output. Here is an example for an Agent which uses DuckDB to store and query data:
You are a helpful assistant which implements a unit test for the "DuckDB" toolkit of functions. Run all of the steps below and make sure to print the result of each step:
1. read the CSV file at the url "https://drive.google.com/uc?id=1zO8ekHWx9U7mrbx_0Hoxxu6od7uxJqWw&export=download" and save it as a file called customers100.csv
2. Read customers100.csv as a dataframe and show the name of the last column
3. Save the customers dataset in parquet format
4. Query the customers dataset and clone each row where the customer name starts with 'S'
5. Now save this new dataset to a parquet file called 'morecustomers.parquet'
6. Verify that the total rows are in this new dataset equals 10
7. If all steps completed successfully, then print "=SUCCESS" otherwise print "=ERROR".
We ask the Agent to execute a series and steps, and then to reflect along the way to ensure that each step (each “unit test”) succeeded. At the end we ask the agent to print "=SUCCESS" or “=ERROR” depending on all the results. As part of a nightly test suite we can run our agent with this prompt, and mechanically test for the presence of the “=SUCCESS” string in the output after each automated run.
Observing Costs
Understanding the cost to run your agent starts with understanding the costs you are paying for LLM tokens. The leading LLM vendors return token usage metadata with their API calls, and you can track this data to total up the tokens used running your agent.
The area of LLM Observability is growing rapidly, and DataDog recently added support in their product. There are also startups offering observability services. Generally this is a good area where you can expect to leverage a pre-existing solution rather than having to build it yourself.
Open Source Agents
To manage costs and control sharing of sensitive information, there is a big push to create open source LLMs that are good enough to replace GPT and Claude in the use of agents. If we could run the model ourselves then inference would be cheaper, and we wouldn’t have to worry about sharing sensitive information with anyone else.
There has been a concerted push by Mistral, Meta, Deepseek, and others to create “GPT4-class” open source LLMs, where both the source code AND training weights of the model are freely available.
However, good agentic behavior relies on more than extensive training data. The models from OpenAI and Anthropic are heavily tuned AFTER the initial training so that they are more reliable “agent brains”. In particular the models are trained to do:
- Perform “chain of thought” reasoning internally without requiring an explicit command
- Do good tool selection and function calling, effectively choosing amongst many functions and composing function parameters
Members of the OSS community create “instruct” versions of popular models, like Llama3.1-instruct, which are fine tuned for agentic behavior. So far we have found Llama3.1-405b-instruct to be the best possible candidate for building effective agents.
But in our testing, no currently available open source LLMs can compete with GPT or Claude models in delivering these agentic features. However, those models can still be used for “simpler” LLM tasks like calculating embeddings, summarization, and code and text generation. So our current recommendation is to test open source models in specific scenarios, but expect that agent orchestration will still work best using a closed-source model.
UPDATE
New kid on the block DeepSeek has upped the ante for capable open source models. It is looking like the era of reasonably cheap, reasonably capable open source LLMs usable for agents is very very close.
Advanced Topics
We have attempted to capture the “applied state of the art” for AI agents in this paper. But research and innovation continue at a rapid pace. The following is a discussion of some of these areas where we expect to see a lot of advancement this year.
Graph RAG
Current RAG architectures based on vector similarity are inherently primitive: they hoover up content “related” to a question by syntactic or semantic similarity, dump it all into LLM context, and then hope the LLM can answer.
But many questions are more “conceptual” queries that can only be answered by understanding the structure of the information that contains the answer. For example, consider a query like “Which customers were impacted by the most production incidents this quarter?”
Your RAG backend can probably return info on incidents, but the relation of those to specific customers may be absent from many of the “chunks” of info.
The idea of Graph RAG is to model your knowledge as a knowledge graph, which identifies key entities like people, companies, customers, and products, and models the relationships between these entities. Unstructured info is then attached to nodes in the graph. Now your knowledge retrieval step could search for incident discussions, but then relate each of these back to a customer entity in the graph.
In this way your agent could index and search for info by its well-structured, semantic meaning, potentially enabling it to answer much more complex and nuanced questions.
Reflection and Learning
The LLM is in reality a filter of sorts which depends on the input given it to predict the “correct” output. In the agentic process, with tool calling provided, this filter will be re-processed again and again with refined inputs that include results from tool calls as the solution gets nearer to completion. It is a given that the agent will make mistakes in this process. Let me list the types of mistakes it will make:
- Tool Calling Errors
While each tool provides a description of its functions—along with the intended purpose and type of each parameter—LLMs often struggle to generate correct or well-structured tool calls. For example, a parameter might require an SQL query string, but the LLM might fail to properly craft this query or provide incomplete arguments. - Hallucinations
Even when no tool calls are involved, LLMs may invent supporting details in an effort to produce a seemingly correct answer. These hallucinations can undermine reliability, leading to inaccurate or fabricated content. - Misinterpretations
An LLM might misunderstand user intent or contextual cues, producing an answer that does not align with what the user actually wants. Identifying the reason for these misunderstandings is crucial for guiding and improving future interactions.
How Reflection Enables Learning
An agentic system that includes reflection can analyze the logs and context of a given “run” to identify whether any of the above errors occurred. By examining its process and outcomes, the system can propose additional explanatory text or “lessons learned” to store as memories. These memories, in turn, inform future agent runs and reduce the likelihood of repeating the same mistakes.
Crucially, the reflection process itself can also be LLM-driven. The system can provide a set of generic instructions—effectively a reflective framework—for the LLM to follow as it analyzes the logs. Based on this guidance, the LLM will generate insights or “nuggets of wisdom” that serve as targeted corrective measures. These insights are then stored as persistent memories, ensuring that subsequent runs benefit from the lessons of the past.
Short-Term Memories: Guardrails and Configurations
Not all memory within an agentic system needs to stem directly from reflection. Some short-term knowledge can simply function as a practical timesaver that allows the LLM to stay “on track” without repeatedly asking or inferring domain-specific details. Short-term memories can include:
- Guardrail Instructions: Configuration data or rules that ensure the LLM generates valid or safe outputs—for instance, guidelines for how to handle sensitive data, instructions for maintaining a particular style or tone, or explicit constraints on what the agent can and cannot do.
- Configuration Details: Subject-specific information, such as the names of databases, tables, or fields; the structure of particular APIs; or how to build an IMAP search string. Storing these details temporarily keeps the LLM from making repeated mistakes and reduces the volume of user-visible prompts.
- Contextual Keys: Minor but essential parameters for tool calls (e.g., specific version numbers or IDs) that need to be repeated across multiple calls. By storing these contextually relevant details in short-term memory, the agent can easily reference them without user intervention.
Because this short-term storage mechanism operates “behind the scenes,” it does not clutter the user’s view with low-level details—yet it maintains consistent and accurate output generation. By seamlessly applying these guardrails and configurations, the agent can focus on solving the user’s problem rather than re-deriving or verifying the same information repeatedly.
Together, reflection-based improvements and short-term guardrails/configuration memories help the agentic system remain efficient, accurate, and user-focused.
Long-term Memory
Most agents today work in “episodic sessions”, often starting with a “blank memory slate” when you start a new session. This is efficient with regards to LLM context since you start with a minimal context each time.
Eventually however, agents should operate with “infinite memory”, compressing and expanding information and experiences as necessary to fit into “short term memory” (LLM context) but without requiring their client to manage that process.
This will engender significant advantages:
- Agents can learn and customize their behavior to fit their “owner” or environment.
- Agents will self-reflect and self-improve by dynamically storing and updating long-term memories.
- Eventually we should expect to see learning, long-term memory, and RAG retrieval merge into a single pool of “unlimited memory”.
We recommend reading about the memory stream architecture from the Generative Agents paper.
Related Reading
The Open Hands agent framework for software coding tasks.
Building Effective Agents from Anthropic
The Agents whitepaper from Google
Agents In Action
Following are some published examples of AI agents in production use. We’ve tried to focus on truly agentic systems, as opposed to more basic workflow systems.
Unity Game Development Assistant: https://www.microsoft.com/en/customers/story/1769469533256482338-unity-technologies-azure-open-ai-service-gaming-en-united-states
Johnson and Johnson uses AI Agents to reduce manual work in drug discovery:
ReconAI from Moody’s, an agent which analyzes company financial indicators to provide early warnings about degradations in company performance.
The OpenHands agent system for software development goes well beyond “chat-based coding” and code completion, offering agents that can plan and execute multi-step development tasks including writing, running, and iterating unit tests.
Atlassian Rovo agents are mostly basic chatbots, but you can create your own agents, with custom instructions, and give those actions JIRA-specific actions like creating or editing JIRA issues.
The company Jumpcut uses an agentic architecture to analyze movie scripts to extract plot, character, and thematic devices.